
我们都曾遇到过在某个时候不得不从网站中提取数据的情况。
例如,在处理新帐户或广告系列时,您可能没有可用于创建广告的数据或信息。
在理想情况下,我们会以易于导入的格式(例如 CSV、Excel 电子表格或 Google 表格)为我们提供所需的所有内容、登录页面和相关信息。(或者至少,提供我们需要的选项卡式数据,可以将其导入上述格式之一。)
但这并不总是这样。
那些缺乏网络抓取工具的人——或者缺乏使用 Python 之类的东西来帮助完成任务的编码知识——可能不得不求助于手动复制和粘贴可能成百上千个条目的繁琐工作。
在最近的一份工作中,我的团队被要求:
- 转到客户的网站。
- 下载分布在 15 个不同页面上的 150 多种新产品。
- 将每个产品的产品名称和着陆页网址复制并粘贴到电子表格中。
现在,您可以想象,如果我们只是这样做并手动执行任务,该任务会有多长。
这不仅耗时,而且有人手动浏览那么多项目和页面,并且必须逐个产品地复制和粘贴数据,犯一两个错误的可能性非常高。
然后将需要更多时间来审查文档并确保它没有错误。
一定有更好的方法。
好消息:有!让我告诉你我们是怎么做到的。
什么是 IMPORTXML?
输入谷歌表格。我希望您了解一下 IMPORTXML 函数。
根据 Google 的支持页面,IMPORTXML“从各种结构化数据类型中导入数据,包括 XML、HTML、CSV、TSV 以及 RSS 和 ATOM XML 提要。”
本质上,IMPORTXML 是一种允许您从网页中抓取结构化数据的功能——无需编码知识。
例如,可以快速轻松地提取页面标题、描述或链接等数据,但也可以提取更复杂的信息。
IMPORTXML 如何帮助抓取网页元素?
该函数本身非常简单,只需要两个值:
- 我们打算从中提取或抓取信息的网页的 URL。
- 以及包含数据的元素的 XPath。
XPath 代表 XML 路径语言,可用于在 XML 文档中浏览元素和属性。
例如,要从 https://en.wikipedia.org/wiki/Moon_landing 中提取页面标题,我们将使用:
=IMPORTXML(“https://en.wikipedia.org/wiki/Moon_landing”, “//title”)
这将返回值:Moon landing – Wikipedia。
或者,如果我们正在寻找页面描述,试试这个:
=IMPORTXML(“https://www.searchenginejournal.com/”,”//meta[@name=’description’]/@content”)
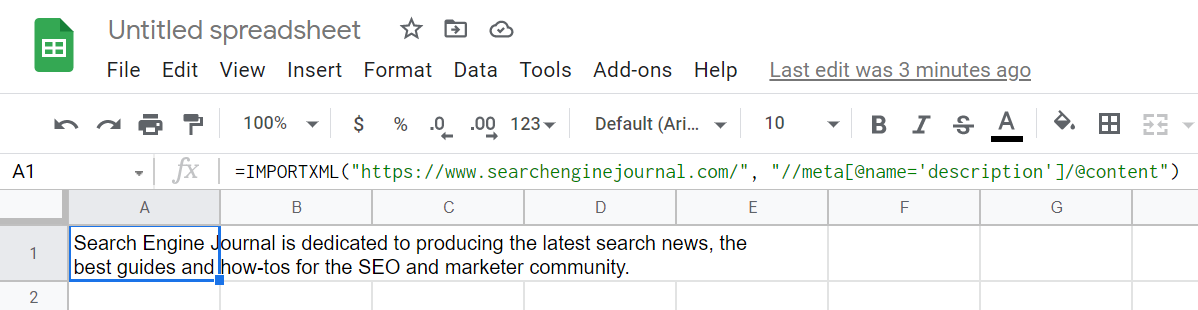
以下是一些最常见和最有用的 XPath 查询的候选清单:
- 页面标题://标题
- 页面元描述://meta[@name=’description’]/@content
- 页面 H1://h1
- 页面链接://@href
查看 IMPORTXML 的实际应用
自从在 Google 表格中发现 IMPORTXML 以来,它真正成为我们许多日常任务自动化的秘密武器之一,从活动和广告创建到内容研究等等。
此外,该函数与其他公式和附加组件相结合,可用于更高级的任务,否则这些任务将需要复杂的解决方案和开发,例如用 Python 构建的工具。
但在本例中,我们将以最基本的形式查看 IMPORTXML:从网页中抓取数据。
让我们看一个实际的例子。
想象一下,我们被要求为 Search Engine Journal 创建一个活动。
他们希望我们在网站的 PPC 部分宣传最近发表的 30 篇文章。
您可能会说,这是一项非常简单的任务。
不幸的是,编辑们无法向我们发送数据,并请我们参考该网站以获取设置活动所需的信息。
正如我们文章开头提到的,一种方法是打开两个浏览器窗口——一个是网站,另一个是 Google 表格或 Excel。然后我们将开始逐条复制和粘贴信息,逐个链接。
但是在 Google 表格中使用 IMPORTXML,我们可以在很短的时间内获得相同的输出,几乎没有犯错的风险。
就是这样。
第 1 步:从全新的 Google 表格开始
首先,我们打开一个新的空白 Google 表格文档:
第 2 步:添加您需要抓取的内容
添加我们要从中抓取信息的页面(或页面)的 URL。
在我们的例子中,我们从 https://www.searchenginejournal.com/category/pay-per-click/ 开始:
截取自 Google 表格的屏幕截图,2021 年 7 月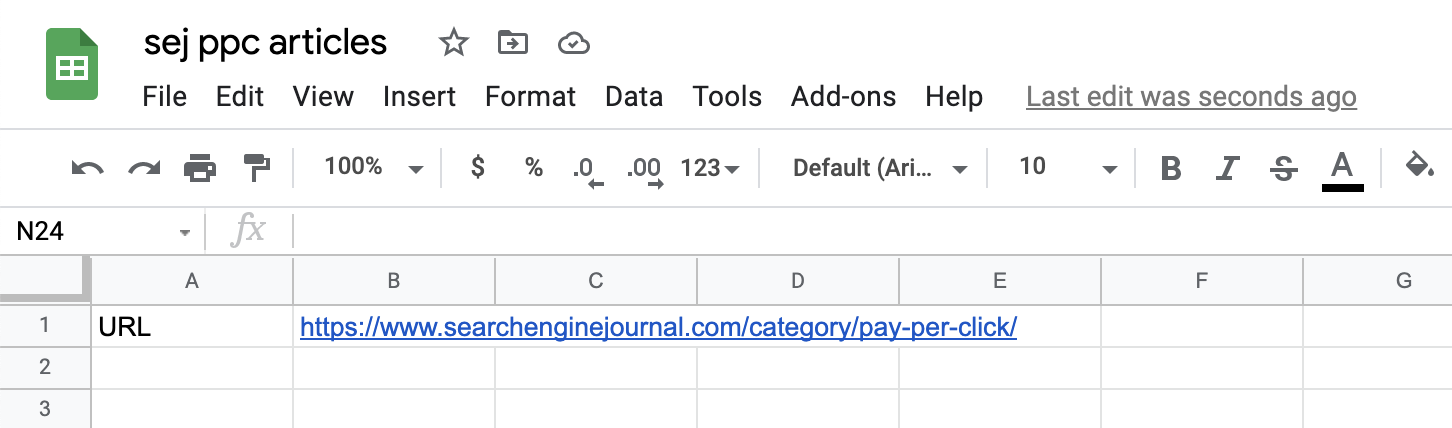
第 3 步:找到 XPath
我们找到要将其内容导入数据电子表格的元素的 XPath。
在我们的示例中,让我们从最近 30 篇文章的标题开始。
前往 Chrome。将鼠标悬停在其中一篇文章的标题上后,右键单击并选择检查。
SearchEngineJournal.com 的屏幕截图,2021 年 7 月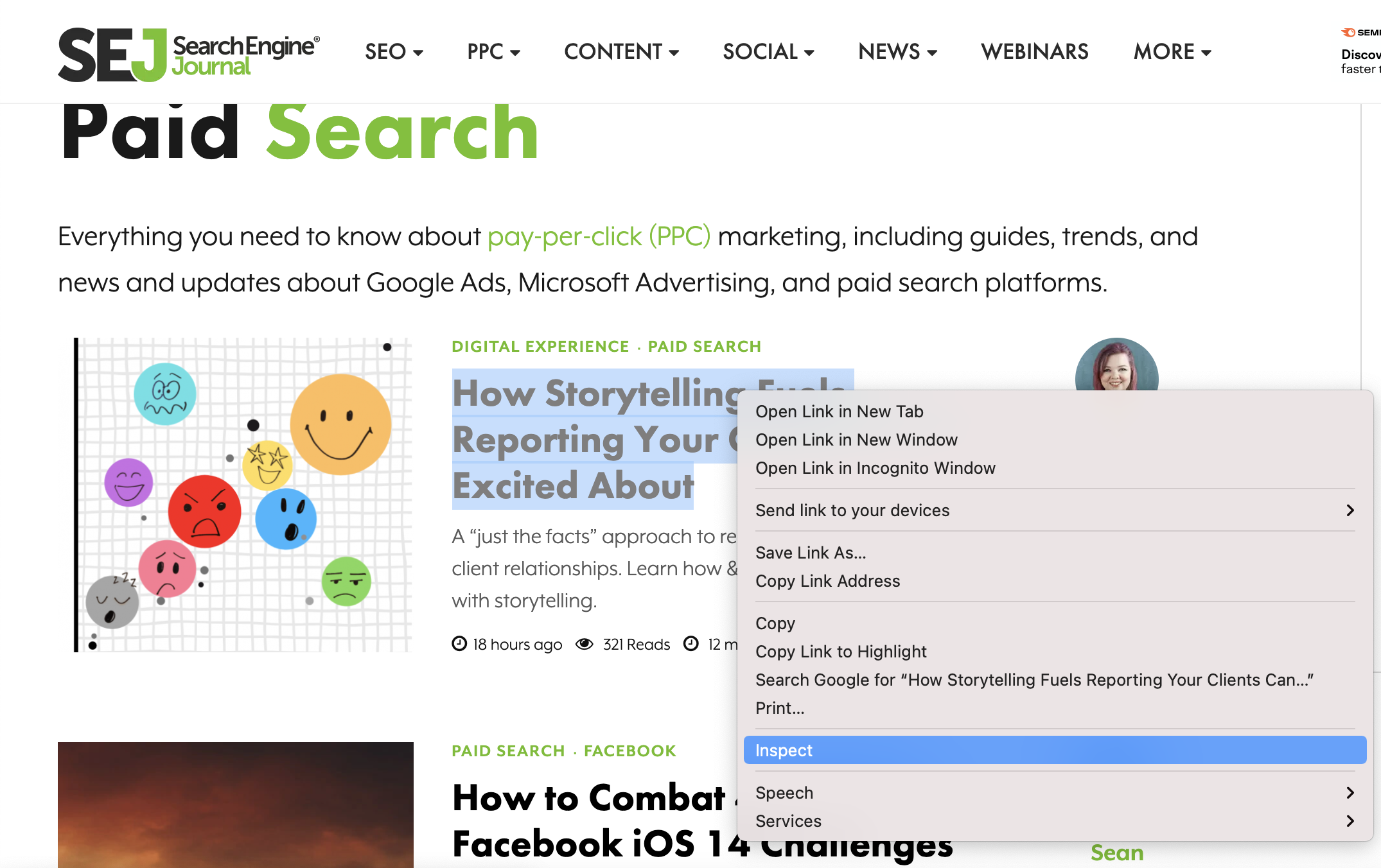
这将打开 Chrome 开发工具窗口:
SearchEngineJournal.com 的屏幕截图,2021 年 7 月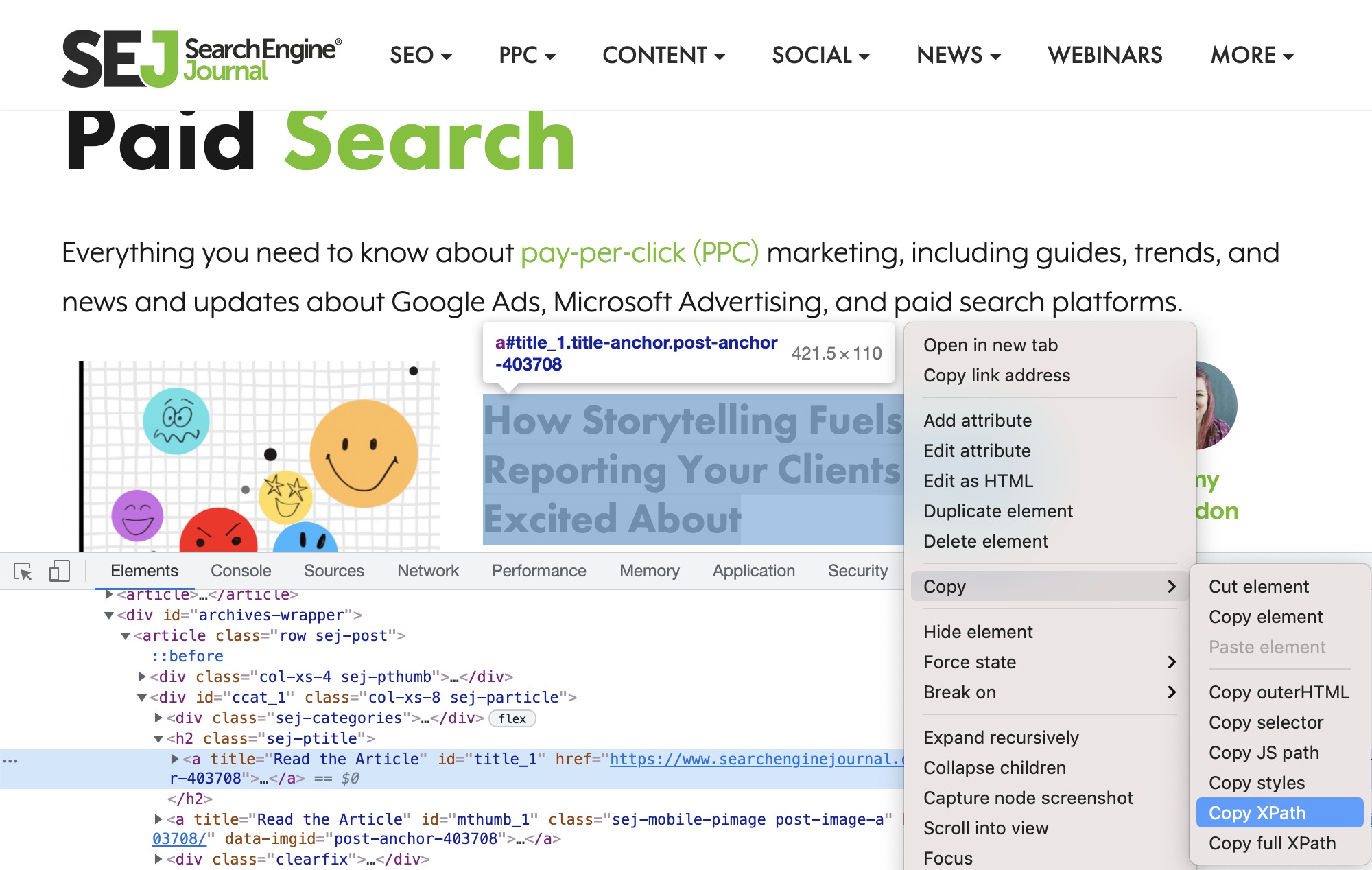
确保文章标题仍处于选中状态并突出显示,然后再次右键单击并选择“复制”>“复制 XPath”。
第 4 步:将数据提取到 Google 表格中
回到你的 Google Sheets 文档中,引入 IMPORTXML 函数,如下所示:
=IMPORTXML(B1,”//*[开头为(@id, ‘title’)]”)
有几点需要注意:
首先,在我们的公式中,我们将页面的 URL 替换为对存储 URL 的单元格 (B1) 的引用。
其次,当从 Chrome 复制 XPath 时,这将始终用双引号引起来。
(//*[@id=”title_1″])
但是,为了确保它不会破坏公式,需要将双引号更改为单引号。
(//*[@id=’title_1′])
请注意,在这种情况下,因为每篇文章的页面 ID 标题都会发生变化(title_1、title_2 等),我们必须稍微修改查询并使用“starts-with”以捕获页面上 ID 包含的所有元素’标题。’
以下是 Google 表格文档中的内容:
截取自 Google 表格的屏幕截图,2021 年 7 月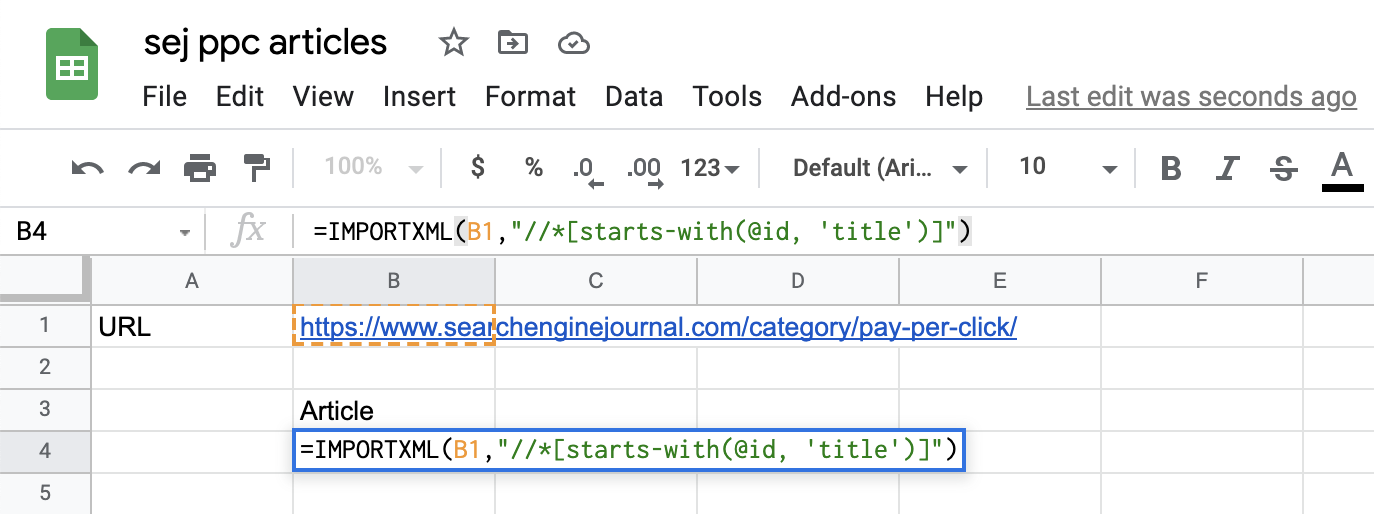
片刻之后,查询将数据加载到电子表格后,结果如下所示:
截取自 Google 表格的屏幕截图,2021 年 7 月
如您所见,该列表返回了我们刚刚抓取的页面上的所有文章(包括我之前关于自动化以及如何使用广告定制器提高 Google Ads 广告系列效果的文章)。
您也可以将其应用于抓取设置广告活动所需的任何其他信息。
让我们将登陆页面 URL、每篇文章的特色片段和作者姓名添加到我们的表格文档中。
对于着陆页 URL,我们需要调整查询以指定我们在附加到文章标题的 HREF 元素之后。
因此,我们的查询将如下所示:
=IMPORTXML(B1,”//*[开头为(@id, ‘title’)]/@href”)
现在,将“/@href”附加到 Xpath 的末尾。
截取自 Google 表格的屏幕截图,2021 年 7 月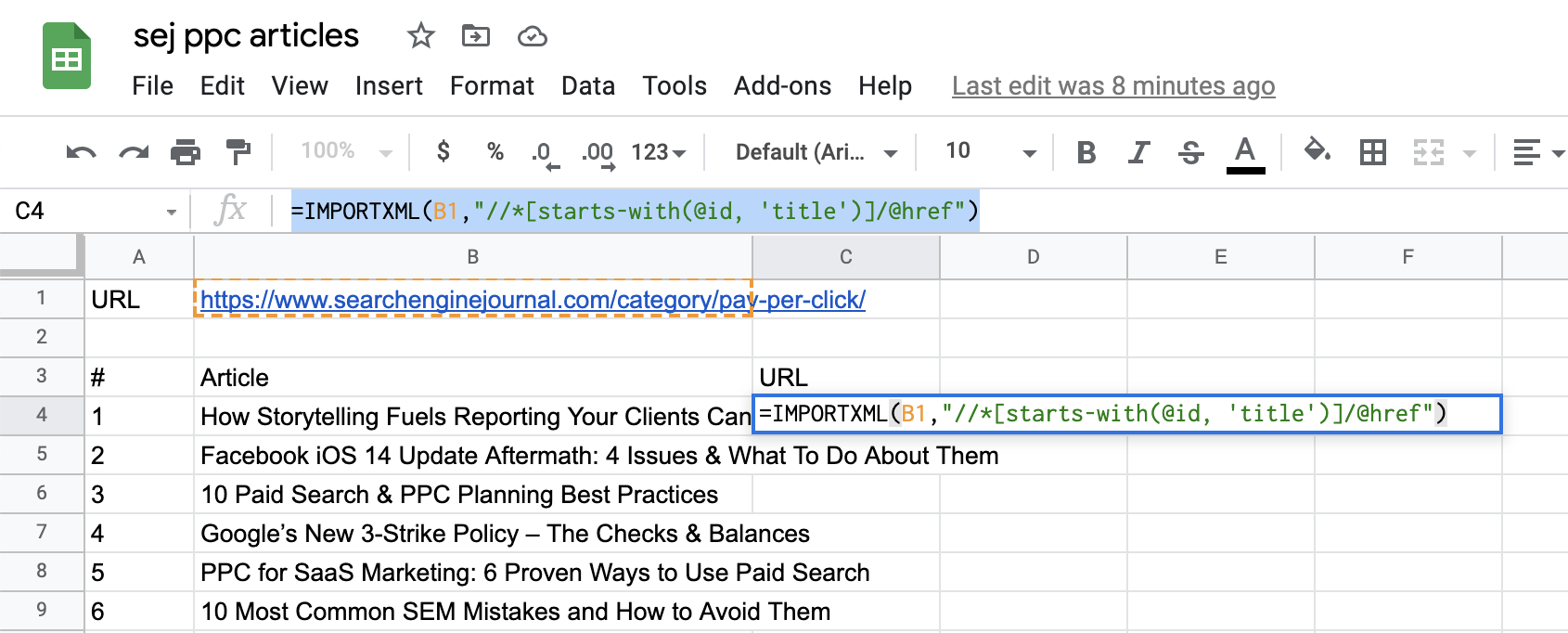
瞧!马上,我们就有了着陆页的 URL:
截取自 Google 表格的屏幕截图,2021 年 7 月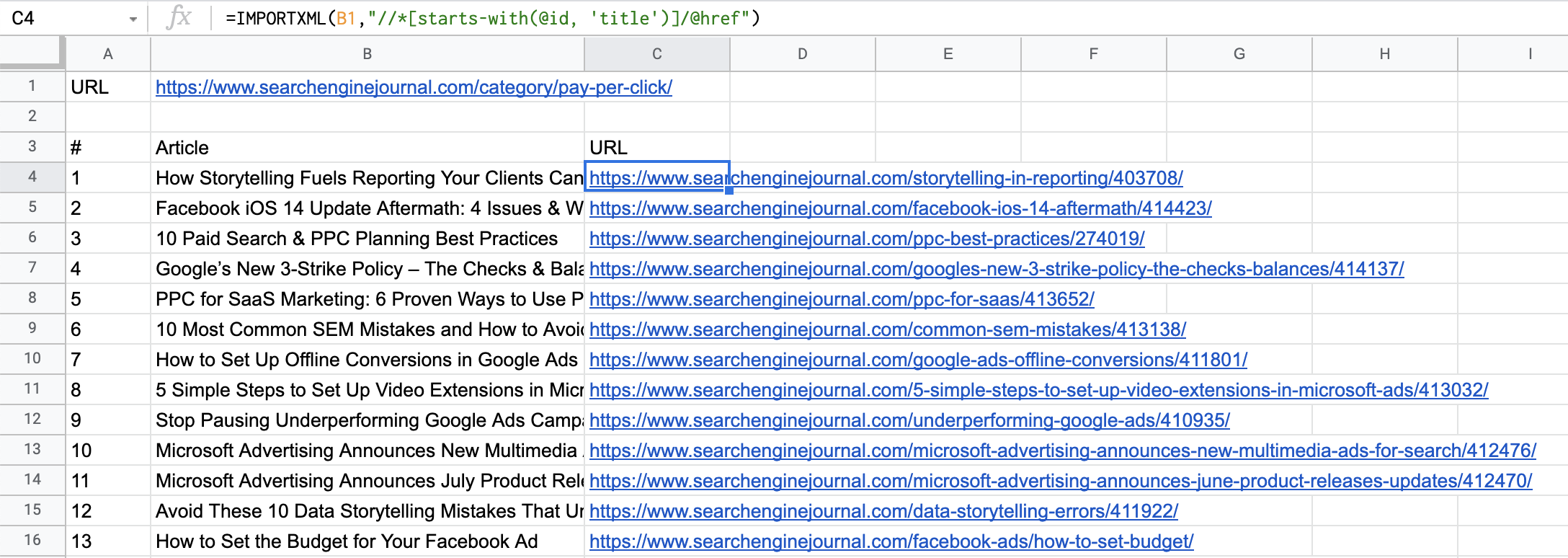
您可以对特色片段和作者姓名执行相同的操作:
截取自 Google 表格的屏幕截图,2021 年 7 月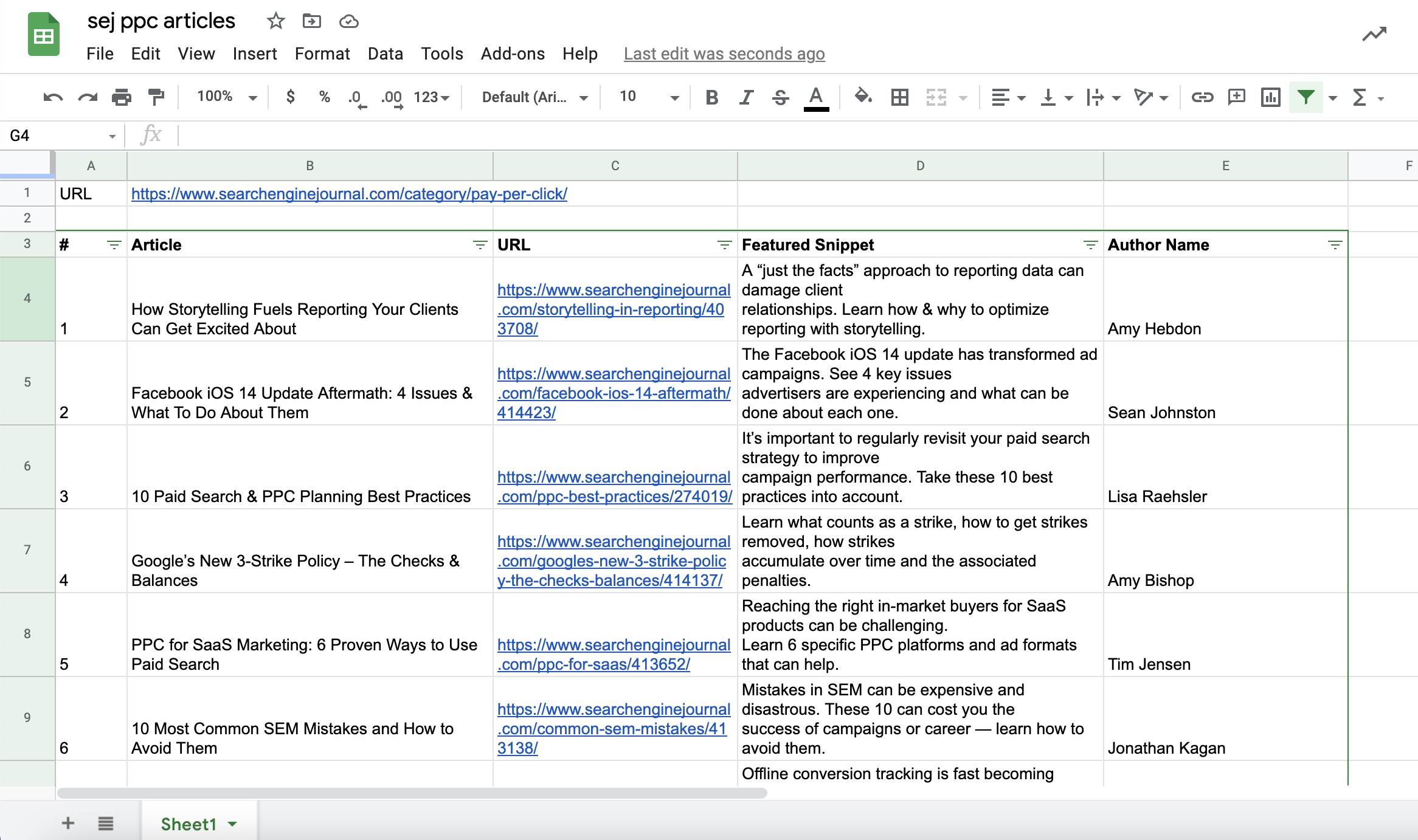
故障排除
需要注意的一件事是,为了能够使用查询返回的所有数据完全扩展和填充电子表格,填充数据的列必须有足够的空闲单元格并且没有其他数据挡道。
这与我们使用 ARRAYFORMULA 时的工作方式类似,要展开的公式必须在同一列中没有其他数据。
结论
并且你有一个完全自动化、无错误的方式来从(可能)任何网页上抓取数据,无论你需要内容和产品描述,还是电子商务数据,如产品价格或运费。
在信息和数据可以成为提供比平均结果更好所需的优势的时代,以简单快捷的方式抓取网页和结构化内容的能力可能是无价的。此外,正如我们在上面看到的,IMPORTXML 可以帮助缩短执行时间并减少出错的机会。
此外,该功能不仅是一个可以专门用于 PPC 任务的好工具,而且可以在许多需要网络抓取的不同项目中真正有用,包括 SEO 和内容任务。
2021 SEJ 圣诞节倒计时:
- #12 – 新的 Google 业务简介:本地 SEO 的完整指南
- #11 – 如何使用 Python 通过搜索意图自动进行 SEO 关键字聚类
- #10 – 了解 Google Analytics 4:完整指南
- #9 – 我希望在我的 SEO 职业生涯中早点知道的 7 件事
- #8 – 针对 Google 新闻、头条新闻和发现进行优化的指南
- #7 – 关键字集群:如何提升您的 SEO 内容策略
- #6 – 高级核心网络生命力:技术 SEO 指南
- #5 – 如何使用 Google 表格进行网页抓取和活动构建